Learning pick-and-place with behavior cloning and offline multi-agent reinforcement learning
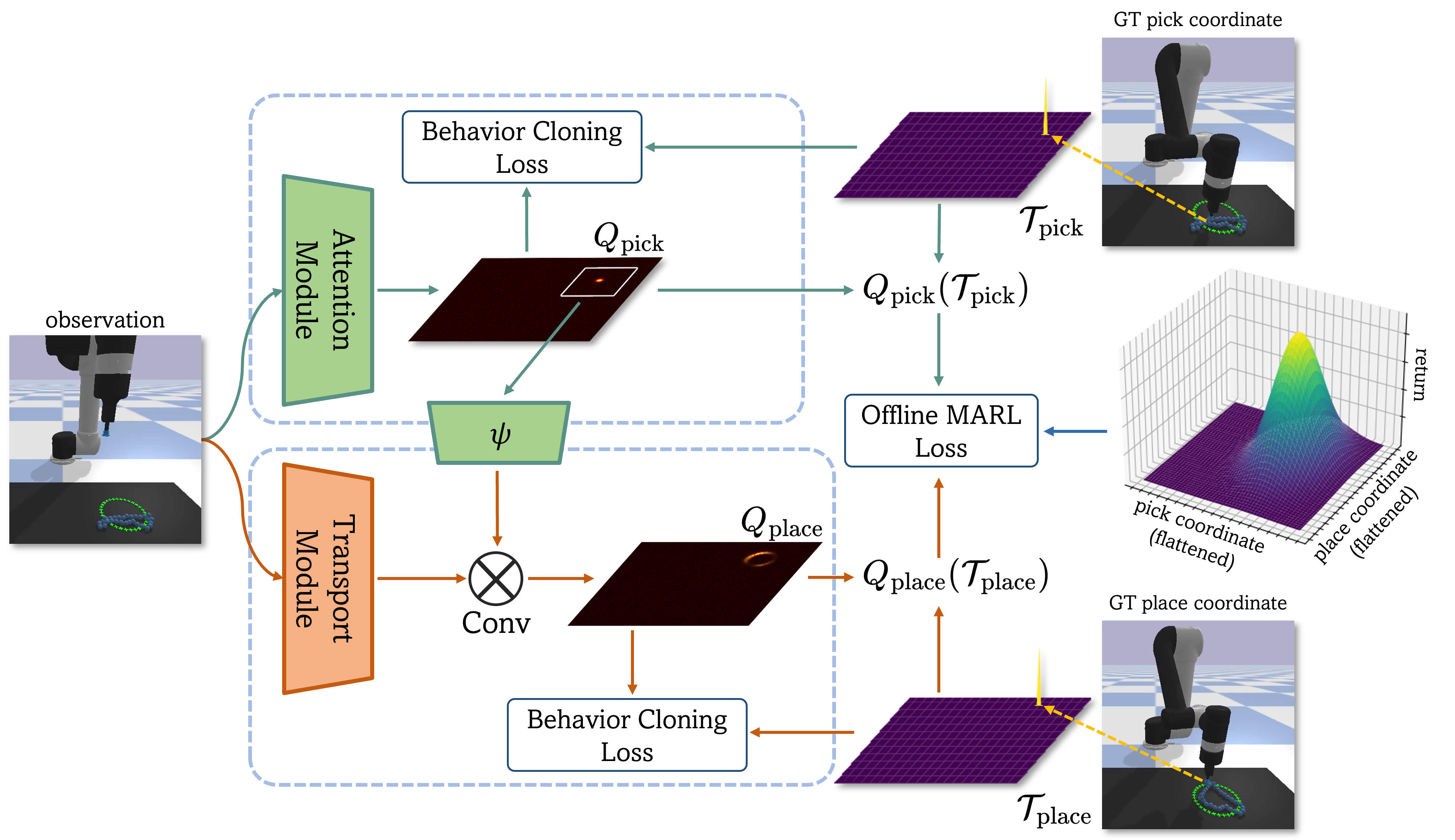
In this work, we propose CoTransporter that combines the Transporter Networks and offline multi-agent reinforcement learning (MARL) to learn to manipulate objects with imperfect demonstrations. We demonstrate that behavior cloning using cross entropy loss is at odds with accurate Q-value learning. To rectify this, we constrain the Q-value networks to output-bounded networks. With a sufficiently large range, these networks can effectively balance the objectives of behavior cloning and Q-value learning.
We further propose to estimate the offline MARL objective with a sparse reward function and no additional information is required. The goal reward within this sparse reward function is correlated with the Q-value networks and can be determined regardless of the specific task. Although learning from a sparse reward in an offline fashion is challenging, CoTransporter utilize behavior cloning to prevent convergence to a sub-optimal policy and meanwhile learn a policy that significantly surpasses one that merely mimics demonstrations.
Furthermore, we address the instability arising from direct optimization of the MARL objective, as the place agent relies on the pick agent's output. We optimize a novel objective to enforce collaboration between pick and place agents and meanwhile to ensure stable improvements individually. The figure summarizes our method of estimating behavior cloning and offline MARL objectives.

